

故障转储,问题诊断与解决方案的全面指南

故障转储、问题诊断与解决方案的全面指南,旨在帮助用户快速定位和解决计算机系统或应用中出现的各种问题。该指南首先介绍了故障转储的概念和重要性,包括如何生成和解析故障转储文件,以便于问题诊断。它详细阐述了问题诊断的步骤和方法,包括使用日志文件、监控工具、性能分析工具等手段,以及如何根据错误代码和异常信息来识别和分类问题。,,在解决方案部分,该指南提供了针对常见问题的具体操作步骤和技巧,如修复系统漏洞、优化配置、更新软件等。它也强调了预防措施的重要性,如定期备份数据、更新系统和软件、进行安全检查等,以减少未来出现问题的可能性。,,该指南还提供了实用的建议和最佳实践,如如何有效地与技术支持团队沟通、如何制定和维护问题解决流程等。这些内容对于提高问题解决效率和减少问题复现率具有重要意义。,,该指南是解决计算机系统或应用中问题的全面指导,从故障转储的生成和解析到问题诊断和解决方案的制定,都提供了详细的步骤和方法。它不仅适用于IT专业人员,也适用于普通用户,帮助他们更好地理解和解决计算机中出现的问题。
在当今的数字化时代,计算机系统与网络设备在各行各业中扮演着至关重要的角色,随着技术的复杂性和依赖性的增加,系统故障也变得日益常见,当系统遇到无法即时处理的问题时,故障转储(Crash Dump)作为一种重要的诊断工具,能够帮助我们理解故障的根源,进而采取有效的解决措施,本文将深入探讨故障转储的概念、类型、重要性以及如何有效解决由其揭示的问题。

一、故障转储的基本概念
故障转储,也称为崩溃转储或错误转储,是指当计算机程序或系统因异常情况(如软件错误、硬件故障或操作系统问题)而突然终止时,系统自动将程序当前的状态、内存内容、寄存器状态等信息保存到磁盘或其他存储介质上的过程,这一过程对于后续的故障分析和问题解决至关重要。
二、故障转储的类型
根据不同的触发条件和保存内容,故障转储主要分为以下几种类型:
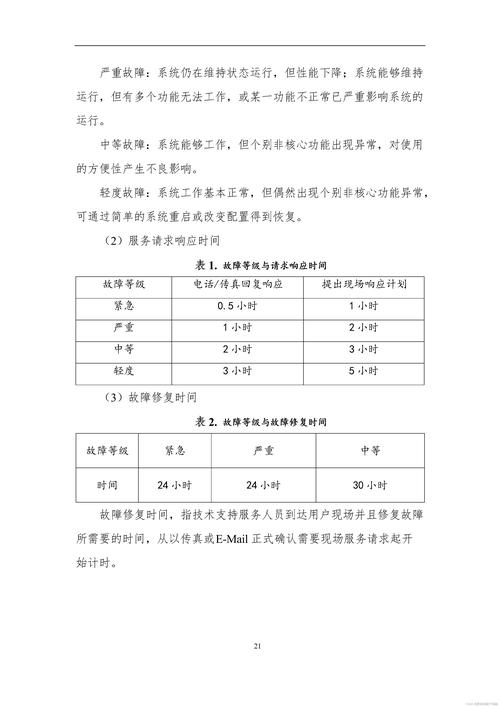
1、内核转储(Kernel Dump):当操作系统内核崩溃时,会生成一个包含内核内存、寄存器状态等关键信息的转储文件,这对于操作系统级别的错误诊断尤为重要。
2、用户模式转储(User-Mode Dump):当用户级应用程序崩溃时,会生成包含应用程序内存、堆栈信息等的转储文件,这类转储对于开发者定位应用程序中的错误非常有帮助。

3、完全转储(Full Dump):保存进程的完整内存映像,包括代码、数据和堆栈等所有信息,这种转储最为全面,但也会占用较大的存储空间和时间。
4、增量转储(Incremental Dump):只保存自上次转储以来发生变化的内存区域,这种方式可以减少存储需求和转储时间,但需要与之前的转储文件一起分析。
5、写前转储(Write-Before-Crash Dump):在程序崩溃前自动触发一次完整的内存快照,确保在崩溃时刻的完整状态被记录,这对于捕捉瞬时错误非常有效。
三、故障转储的重要性
1、问题诊断:通过分析故障转储文件,开发人员和系统管理员可以快速定位问题发生的具体位置和原因,大大缩短了问题解决的时间。
2、性能优化:了解系统在特定条件下的行为可以帮助优化代码和系统配置,减少未来发生类似问题的可能性。
3、安全审计:在某些情况下,故障转储还可以作为安全审计的一部分,帮助识别潜在的安全漏洞或恶意行为。
四、如何解决由故障转储揭示的问题
1、分析转储文件:使用专门的工具(如Windows的Debugging Tools for Windows, Linux的gdb或Valgrind)来分析转储文件,这些工具能够提供关于崩溃原因的详细信息,如内存访问违规、堆栈跟踪等。
2、代码审查:根据转储分析的结果,仔细审查相关代码段,检查是否存在未初始化的变量使用、数组越界、空指针解引用等常见错误。
3、重现问题:尝试在开发环境中重现问题,这有助于进一步验证问题原因并测试修复的代码,使用相同的输入条件或触发条件来模拟崩溃场景是关键。
4、修复与测试:一旦找到问题根源,进行必要的代码修复或配置更改,之后进行充分的测试,确保问题被正确解决且不会引入新的问题。
5、更新文档与培训:将修复过程和结果记录在开发文档中,并确保团队成员了解最新的变更和最佳实践,这有助于未来更快地响应类似问题。
6、增强系统稳定性:除了针对特定问题的修复外,还可以考虑实施更广泛的措施来增强系统的稳定性和容错性,如增加异常处理逻辑、使用更健壮的库等。
五、实际案例分析
以一个常见的Web服务器应用程序为例,当其因内存泄漏导致频繁崩溃时,首先会生成大量的内核转储文件,通过分析这些文件,发现是由于某个特定模块在处理大量数据时未能正确释放内存造成的,开发团队随后对该模块进行了重构,增加了自动内存管理的逻辑,并进行了严格的测试以确保问题被彻底解决,还对全系统的内存管理策略进行了优化,以防止未来类似问题的发生,这一系列措施不仅解决了当前的危机,还提升了整个系统的稳定性和可靠性。
故障转储是理解和解决复杂系统问题的关键工具,通过合理利用这一机制,我们可以显著提高问题解决的效率,减少系统停机时间,并增强系统的整体健壮性,为了更好地利用故障转储,建议:
- 定期对团队成员进行相关培训,确保每个人都了解如何生成、分析和处理转储文件。
- 实施自动化的监控和报警系统,以便在问题发生时能迅速响应并收集必要的信息。
- 维护一个全面的错误报告和修复数据库,以便快速查找和引用以前的解决方案。
- 鼓励开发人员编写健壮的代码和进行充分的测试,以减少潜在问题的发生。
- 定期回顾和分析转储数据中的模式和趋势,以发现可能被忽视的系统级问题或性能瓶颈。
通过这些措施的实施,我们可以更有效地利用故障转储这一宝贵资源,为构建更加稳定、可靠的系统奠定坚实的基础。



