

Flask与Scrapy,构建高效Web爬虫的完美组合

Flask与Scrapy是构建高效Web爬虫的完美组合。Flask是一个轻量级Web框架,用于构建Web应用程序,而Scrapy是一个强大的网络爬虫框架,可以快速抓取网页数据。结合两者,开发者可以轻松创建出高效、稳定的Web爬虫,实现快速、准确地抓取网页信息,为数据分析、信息挖掘等提供有力支持。
在当今互联网时代,数据获取变得越来越重要,Flask和Scrapy是两个在Python开发中广泛使用的工具,分别用于构建Web应用程序和Web爬虫,本文将探讨如何将Flask和Scrapy结合起来,构建一个高效、灵活的Web爬虫系统。
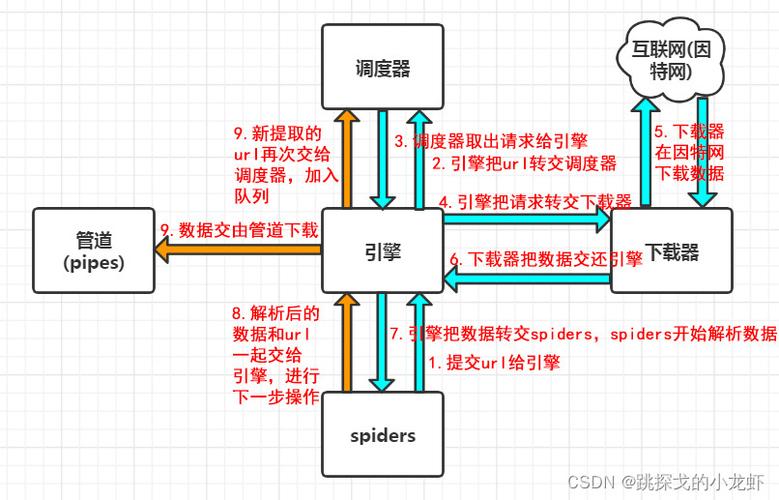
Flask简介
Flask是一个轻量级的Web应用框架,采用Python语言编写,它提供了基本的路由、模板、会话等Web开发功能,同时保持了高度的灵活性和可扩展性,Flask适用于小型到中型规模的Web应用开发,可以方便地与各种数据库、表单处理库等集成。
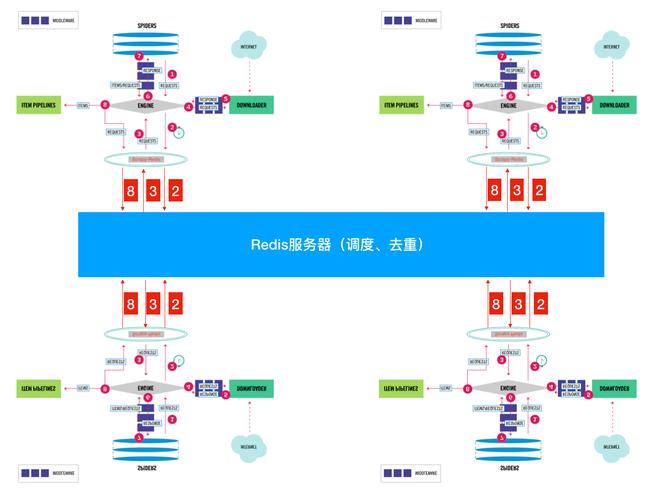
Scrapy简介
Scrapy是一个用于网络爬虫开发的框架,同样采用Python编写,它提供了强大的爬虫引擎、灵活的调度器、丰富的选择器以及强大的数据存储功能,Scrapy适用于大规模的数据采集任务,可以高效地抓取网页数据,并进行清洗、存储和分析。
Flask与Scrapy的结合
虽然Flask和Scrapy各自功能强大,但在实际项目中,我们常常需要将它们结合起来使用,一个典型的场景是:通过Flask提供Web接口,用户可以提交爬虫任务、查看爬取结果等;而Scrapy则负责执行具体的爬虫任务,将抓取到的数据存储到数据库或文件中。
1、任务调度与执行
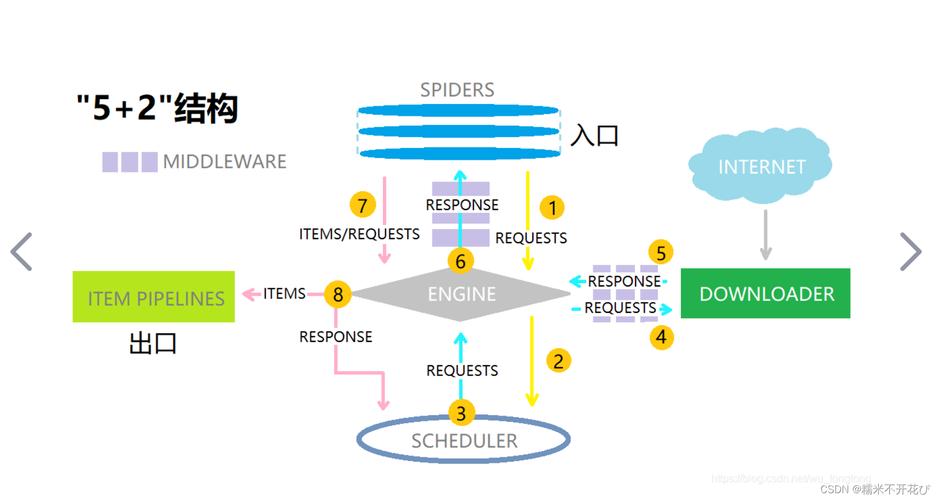
在Flask应用中,我们可以提供一个Web接口,让用户提交爬虫任务,当用户提交任务时,Flask后端将任务信息保存到数据库或消息队列中,通过定时任务或后台服务,启动Scrapy爬虫引擎执行相应的爬虫任务,这样,用户可以通过Flask提供的Web接口方便地管理Scrapy爬虫任务。
2、数据存储与展示
Scrapy爬虫抓取到的数据需要存储起来以便后续分析和使用,Flask后端可以与数据库、文件系统等集成,将Scrapy抓取的数据存储到数据库或文件中,Flask还可以提供Web页面或API接口,让用户查看爬取结果、进行数据分析和可视化等操作,这样,用户可以通过Flask提供的Web界面方便地查看和管理Scrapy抓取的数据。
3、扩展性与灵活性
Flask和Scrapy的结合具有很高的扩展性和灵活性,Flask提供了丰富的插件和扩展库,可以方便地集成各种功能模块,如用户认证、权限管理、日志记录等,而Scrapy则提供了强大的爬虫引擎和灵活的选择器,可以轻松地处理各种复杂的爬虫任务,Flask和Scrapy都采用了模块化设计,方便我们根据项目需求进行定制和扩展。
Flask和Scrapy是两个非常优秀的工具,分别适用于Web应用开发和网络爬虫开发,将它们结合起来使用,可以构建一个高效、灵活的Web爬虫系统,通过任务调度与执行、数据存储与展示以及扩展性与灵活性等方面的探讨,我们可以看到Flask与Scrapy的结合具有很大的潜力和优势,在实际项目中,我们可以根据具体需求选择合适的工具和技术栈,以实现高效的数据采集和分析。



