

C语言中的冒泡排序法

冒泡排序法是C语言中一种简单的排序算法。其基本思想是:通过多次遍历待排序的序列,每次遍历时将相邻的两个元素进行比较,如果顺序错误则交换它们的位置。这个过程会一直重复,直到没有需要交换的元素为止,此时序列已经排好序。冒泡排序法具有简单易懂、易于实现的优点,但时间复杂度较高,不适合大规模数据的排序。
在计算机编程中,排序算法是一种非常重要的算法,它被广泛应用于各种数据处理和数据分析的场景中,冒泡排序法(Bubble Sort)是一种简单的排序算法,其基本思想是通过多次遍历待排序的序列,比较相邻元素的大小关系,并进行交换,使得每一轮遍历后最大(或最小)的元素能够“冒泡”到序列的一端,这种排序方法在C语言中实现起来相对简单,因此被广泛使用。
冒泡排序法的基本原理
冒泡排序法的基本原理是通过多次遍历待排序的序列,比较相邻元素的大小关系,在每一次遍历过程中,如果发现相邻的两个元素顺序错误(即前一个元素大于后一个元素),则交换这两个元素的位置,这样,一轮遍历后,最大(或最小)的元素就会被“冒泡”到序列的一端,再对剩余的未排序元素进行同样的操作,直到整个序列都被排好序为止。
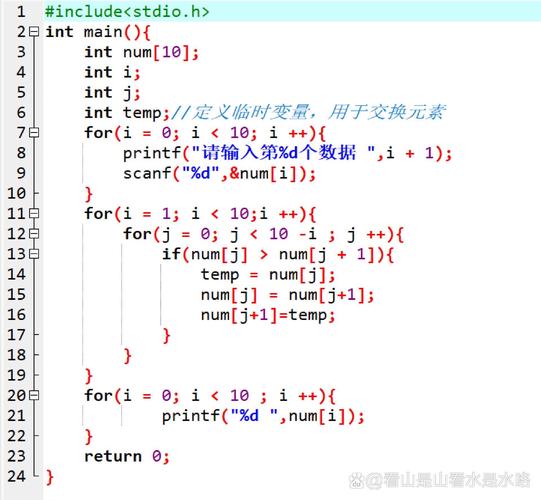
C语言实现冒泡排序法
在C语言中,实现冒泡排序法的基本思路是定义一个函数,该函数接受一个整型数组和数组的长度作为参数,然后通过嵌套的循环结构来遍历和比较数组中的元素,下面是一个简单的冒泡排序法的C语言实现代码:

void bubbleSort(int arr[], int n) {
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
// 交换相邻元素的位置
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}在这个代码中,外层循环控制遍历的次数,内层循环则负责比较和交换相邻元素的位置,当一轮遍历结束后,最大(或最小)的元素就会被“冒泡”到序列的一端,再对剩余的未排序元素进行同样的操作,直到整个序列都被排好序为止。
冒泡排序法的优缺点及改进方向
优点:冒泡排序法实现简单,易于理解,对于小规模的数据排序效率较高,由于它的算法逻辑相对简单,因此适合初学者学习和掌握。

缺点:尽管冒泡排序法在小规模数据上的表现尚可,但在大规模数据上的性能较差,由于它需要进行多次遍历和比较操作,时间复杂度较高(O(n^2)),因此在处理大量数据时效率较低,由于它需要不断地交换元素的位置,因此空间复杂度也较高。
改进方向:针对冒泡排序法的缺点,我们可以考虑采用一些更高效的排序算法来替代它,快速排序、归并排序、堆排序等算法在处理大规模数据时具有更高的效率,我们也可以对冒泡排序法进行一些优化操作来提高其性能,可以在每次遍历后只对未排好序的部分进行操作等。
冒泡排序法是一种简单易懂的排序算法,在C语言中实现起来相对简单,虽然它在处理大规模数据时效率较低,但在小规模数据上仍然具有一定的应用价值,通过对冒泡排序法的理解和掌握,我们可以更好地理解其他更高效的排序算法的基本原理和实现方法,掌握冒泡排序法对于计算机编程初学者来说具有重要的意义。



