

Spring Boot 接入 Kafka 的实践与探索

摘要:,,本文介绍了Spring Boot接入Kafka的实践与探索。通过详细步骤,阐述了如何在Spring Boot项目中集成Kafka,包括配置Kafka生产者和消费者的基本步骤,以及如何使用Spring Boot的自动配置功能简化Kafka的使用。本文还探讨了Kafka在微服务架构中的应用,以及如何利用Kafka实现消息队列、数据流处理等功能。实践证明,Spring Boot与Kafka的集成可以有效地提高系统的可扩展性和可靠性。
随着企业级应用对实时数据处理和消息队列的需求日益增长,Kafka 因其高吞吐量、高可靠性以及丰富的功能,成为了许多企业首选的消息中间件,Spring Boot,作为简化 Spring 应用的快速开发工具,与 Kafka 的集成也变得尤为重要,本文将详细介绍如何使用 Spring Boot 接入 Kafka,包括其基本原理、配置方法、以及实际开发中的实践应用。
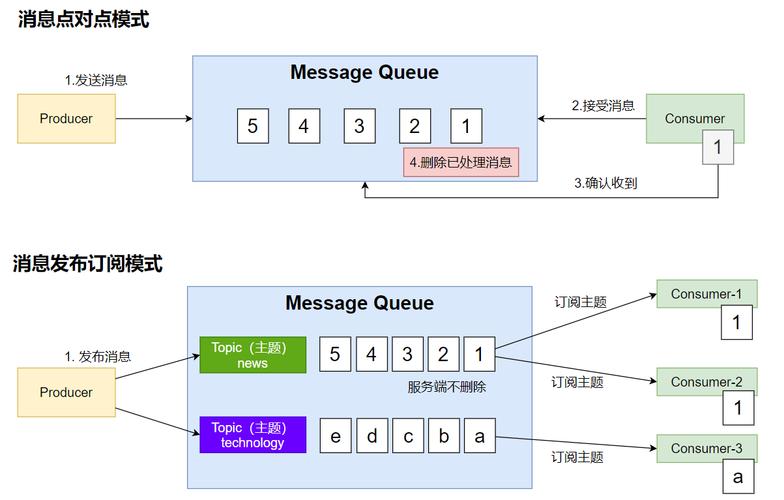
Kafka 基础原理
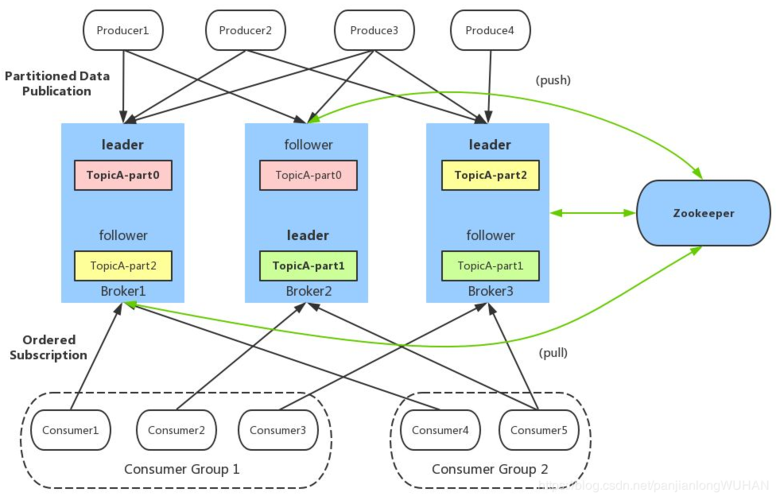
Kafka 是一个分布式流处理平台,主要用于构建实时数据流处理管道和应用程序,它允许发布和订阅记录流,类似于消息队列或企业消息系统,Kafka 的核心概念包括 Producer(生产者)、Consumer(消费者)和 Topic(主题),生产者负责向 Kafka 发送消息,消费者从 Kafka 中读取消息,而主题则是消息的分类和存储单位。
三、Spring Boot 接入 Kafka 的准备工作
在开始之前,需要确保已经安装了 Java 和 Maven 环境,并且已经安装了 Kafka,还需要在 Spring Boot 项目中添加 Kafka 的依赖,在 Maven 的 pom.xml 文件中添加如下依赖:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>最新版本</version> <!-- 请使用最新的稳定版本 -->
</dependency>Spring Boot 配置 Kafka
在 Spring Boot 中接入 Kafka,需要配置相关的参数,在 application.properties 或 application.yml 文件中添加以下配置:
application.properties 示例 spring.kafka.bootstrap-servers=localhost:9092 # Kafka 服务地址 spring.kafka.consumer.group-id=my-group # 消费者组 ID spring.kafka.consumer.auto-offset-reset=earliest # 自动重置偏移量到最早的消息位置 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer # 生产者键序列化器类名 spring.kafka.producer.value-serializer=org.springframework.kafka.support.serializer.JsonSerializer # 生产者值序列化器类名(如果需要 JSON 序列化)
五、创建 Kafka Producer 和 Consumer
1、创建 Kafka Producer:在 Spring Boot 中,可以使用@Service 注解的类中创建一个 Kafka Producer Bean,通过@Autowired 注入KafkaTemplate 或KafkaProducer 来发送消息。
@Service
public class KafkaProducerService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate; // 使用 String 作为键和值的序列化器类型
// ... 其他代码 ... //
public void sendMessage(String topic, String message) {
kafkaTemplate.send(topic, message); // 发送消息到指定主题的 Kafka 中
}
}2、创建 Kafka Consumer:同样地,在 Spring Boot 中创建一个 Kafka Consumer Bean,使用@KafkaListener 注解来监听特定主题的消息。
@Service
public class KafkaConsumerService {
@KafkaListener(topics = "my-topic", groupId = "my-group") // 监听 my-topic 主题的消息,并使用 my-group 组 ID 进行消费处理
public void listen(String message) { // 处理接收到的消息,这里直接打印出来作为示例
System.out.println("Received message: " + message); // 处理接收到的消息逻辑(如保存到数据库等)
}
}实践应用场景与示例代码分析
1、日志收集:使用 Kafka 和 Spring Boot 可以轻松实现日志的收集和实时分析,通过配置 Logback 或 Log4j 等日志框架将日志发送到 Kafka 中,然后使用 Consumer 进行消费和处理,可以实时分析系统日志中的错误信息或统计用户行为等。
2、数据流处理:利用 Kafka 的流处理能力,可以处理实时数据流并执行复杂的业务逻辑,在金融领域中,可以使用 Kafka 处理股票交易数据流,进行实时价格分析和预测等操作,通过编写自定义的 Consumer 处理逻辑,可以实现这些高级功能。
3、微服务通信:在微服务架构中,可以使用 Kafka 作为服务之间的通信机制,通过发布和订阅消息,实现服务之间的解耦和异步通信,一个微服务可以将数据写入 Kafka 中,其他微服务可以订阅该主题并消费数据进行相应的业务处理,这有助于提高系统的可伸缩性和灵活性。
4、示例代码分析:为了更好地理解 Spring Boot 与 Kafka 的集成应用,可以参考以下



