

Spring Boot Kafka 集成,构建高效、可靠的分布式消息系统

摘要:Spring Boot Kafka 集成是一种高效、可靠的分布式消息系统构建方式。通过集成Spring Boot和Kafka,可以快速构建出具有高可用性、可伸缩性和灵活性的消息处理系统。该系统可支持大规模消息的传输和处理,有效提高系统的性能和稳定性。Spring Boot Kafka 集成还提供了丰富的API和工具,方便开发者快速开发和维护分布式消息系统。Spring Boot Kafka 集成是构建高效、可靠分布式消息系统的理想选择。
随着企业级应用的快速发展,消息队列系统在微服务架构中扮演着越来越重要的角色,Spring Boot 和 Kafka 作为两个流行的技术框架,它们的集成能够为企业提供高效、可靠的分布式消息服务,本文将详细介绍如何在 Spring Boot 项目中集成 Kafka,以实现消息的发送、接收和处理。

二、Spring Boot Kafka 集成概述
Spring Boot 和 Kafka 的集成,旨在通过 Spring Boot 的简洁配置和 Kafka 的高吞吐量、高可靠性消息传输能力,为企业级应用提供强大的消息处理能力,通过 Spring Boot Kafka 集成,开发者可以轻松地实现消息的发布、订阅以及复杂的业务逻辑处理。

三、Spring Boot Kafka 集成步骤
1、添加依赖
在 Spring Boot 项目中,首先需要在pom.xml 文件中添加 Kafka 的相关依赖,包括 Spring Boot Kafka 启动器、Kafka 客户端等。
2、配置 Kafka 属性
在application.properties 或application.yml 文件中,配置 Kafka 的相关属性,如 broker 地址、topic 名称、序列化方式等。
3、创建 Kafka 生产者(Producer)和消费者(Consumer)
在 Spring Boot 项目中,通过注解的方式创建 Kafka 生产者和消费者,生产者用于发送消息,消费者用于接收并处理消息。
4、实现业务逻辑
在生产者和消费者的实现类中,编写具体的业务逻辑代码,生产者将业务数据封装成消息并发送到 Kafka,消费者从 Kafka 中订阅 topic 并处理接收到的消息。
四、Spring Boot Kafka 集成关键技术点
1、序列化与反序列化
在 Spring Boot Kafka 集成中,需要对发送和接收的数据进行序列化和反序列化操作,常用的序列化方式包括 JSON 序列化、Avro 序列化等,选择合适的序列化方式可以提高消息的传输效率和处理的便捷性。
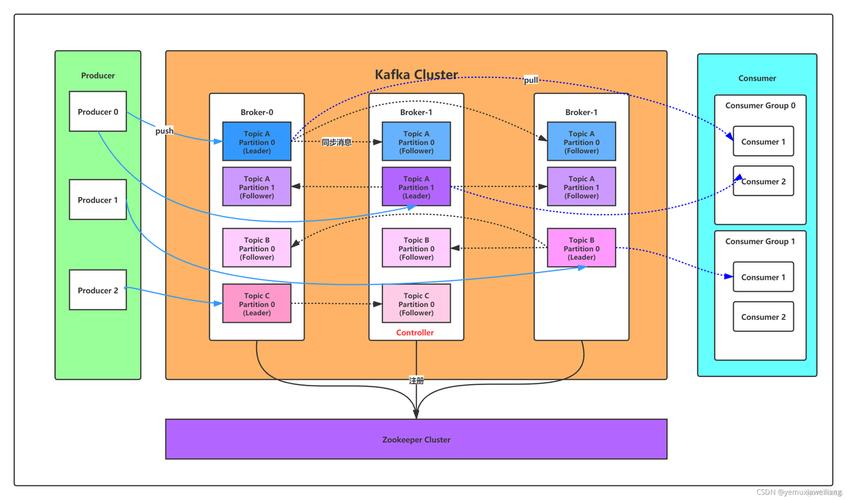
2、消息的分区与复制
Kafka 支持将消息发送到不同的分区(Partition),并通过复制(Replication)机制保证消息的可靠性和容错性,在 Spring Boot Kafka 集成中,需要根据业务需求合理设置分区的数量和复制的因子。
3、消费者组(Consumer Group)
Kafka 支持多个消费者组成一个消费者组(Consumer Group),共同消费同一个 topic 的消息,在 Spring Boot Kafka 集成中,可以通过配置消费者组的 ID 和成员数量,实现消息的并行处理和负载均衡。
五、Spring Boot Kafka 集成的优势与挑战
优势:
1、高性能:Kafka 具有高吞吐量、低延迟的消息传输能力,能够满足企业级应用对消息处理性能的要求。
2、高可靠性:Kafka 通过复制和分区机制保证消息的可靠传输和处理,降低了数据丢失和系统故障的风险。
3、易集成:Spring Boot 的简洁配置和丰富的 API,使得集成 Kafka 变得更加容易和便捷。
挑战:
1、复杂性:虽然 Spring Boot 和 Kafka 的集成相对简单,但仍然需要开发者具备一定的分布式系统和消息队列系统的知识。
2、调优:为了充分发挥 Kafka 的性能和可靠性,需要对系统的参数进行合理的配置和调优,这需要开发者具备一定的系统调优经验和技能。
本文详细介绍了 Spring Boot 和 Kafka 的集成过程及关键技术点,通过 Spring Boot Kafka 集成,企业可以构建高效、可靠的分布式消息系统,实现业务数据的快速传输和处理,未来随着技术的不断发展和进步,Spring Boot 和 Kafka 的集成将更加完善和强大,为企业提供更加优质的服务。



